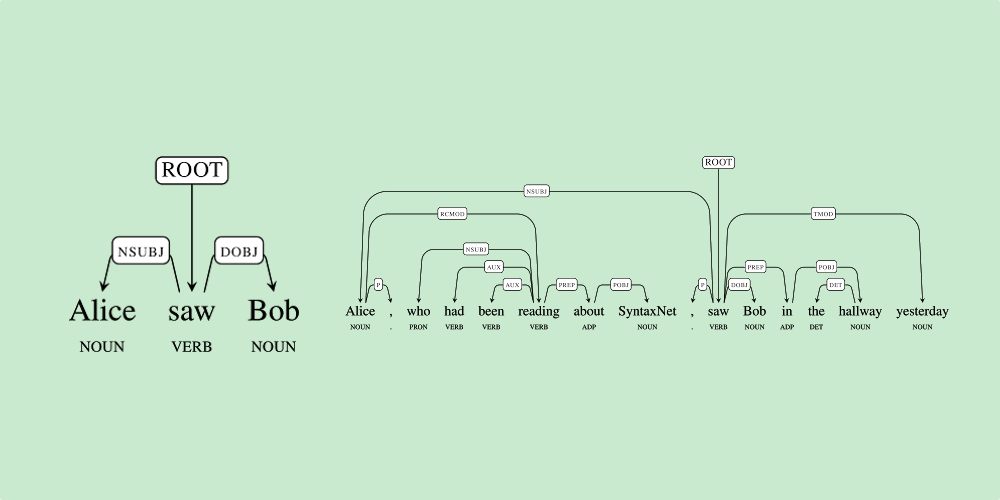
Google announced today that it has open sourced a neural network system called SyntaxNet. This release, Google says “includes all the code needed to train new SyntaxNet models on your own data.” Perhaps more notably, however is the inclusion of “Parsey McParseface” (no, there doesn’t seem to be any real story behind this name), an English parser that the company has pre-trained to analyze English text…
As per the blog post:
Parsey McParseface is built on powerful machine learning algorithms that learn to analyze the linguistic structure of language, and that can explain the functional role of each word in a given sentence. Because Parsey McParseface is the most accurate such model in the world, we hope that it will be useful to developers and researchers interested in automatic extraction of information, translation, and other core applications of NLU.
If you care to read about the technical details of this release, head over to Google’s blog and see SyntaxNet on Github. Basically, Google explains that Parsey McParseface can dissect English sentences (yes, like you probably did in grade school) with about 94% accuracy. Why is “Parsey” even necessary to accomplish this? As Google explains, “ne of the main problems that makes parsing so challenging is that human languages show remarkable levels of ambiguity.” Sentences can mean a lot of things, and Parsey helps figure that out.

FTC: We use income earning auto affiliate links. More.




Comments