
Google announced AI Test Kitchen as a way to let people “learn about, experience, and give feedback on emerging AI technology.” First announced at I/O 2022 in May and rolled out in August, AI Test Kitchen “Season 2” was previewed today with a focus on text-to-image generators.
The existing three demos — Imagine It, List It, and Talk About It — are focused on more conversational experiences powered by LaMDA (Language Model for Dialogue Applications). Season 2, which is coming soon, focuses on text-to-image generation:
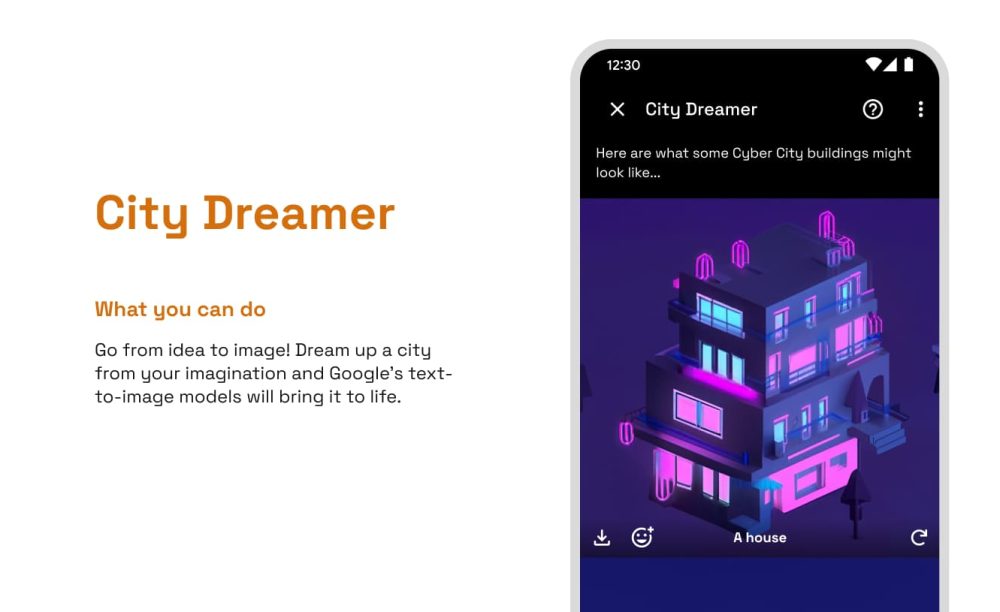
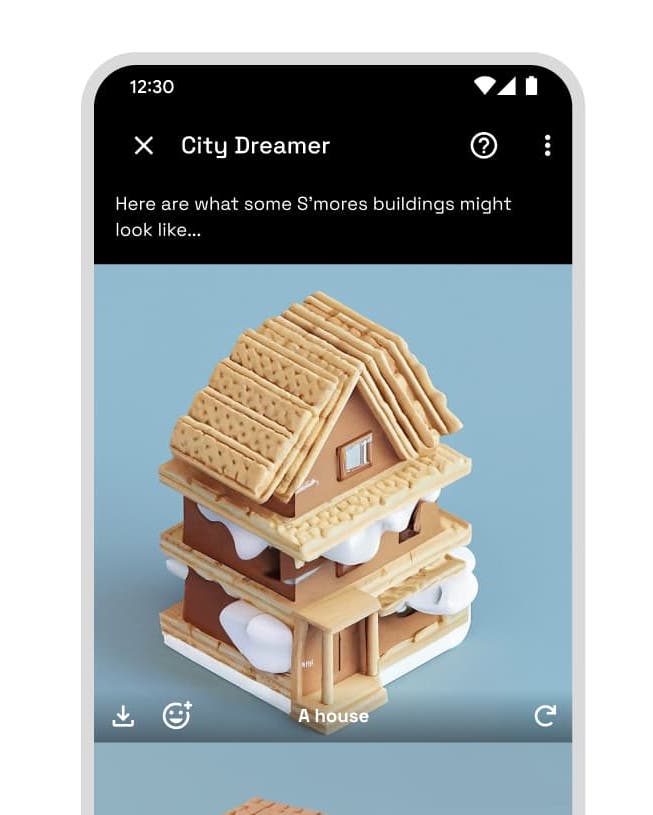
- City Dreamer: Dream up a city from your imagination and Google’s text-to-image models will bring it to life.
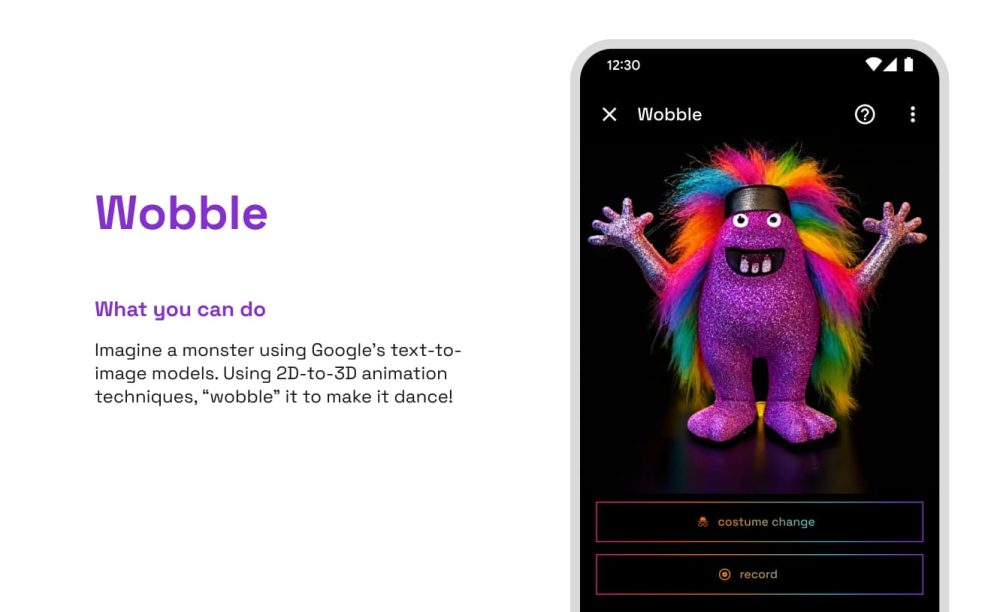
- Wobble: Imagine a monster using Google’s text-to-image models. Using 2D-to-3D animation techniques, “wobble” it to make it dance!
AI Text Kitchen is available in English for Android and iOS users in Australia, Canada, Kenya, New Zealand, UK, and US.
More broadly, Google today detailed work on going from text-to-image to text-to-video models.
- “Imagen Video generates high definition videos using a base video generation model and a sequence of interleaved spatial and temporal video super-resolution models.”
- Phenaki is a “model for generating videos from text, with prompts that can change over time, and videos that can be as long as multiple minutes.”
Combined, Google says you get works that have “super” resolution and “coherence in time.” The examples below were created by Phenaki with Imagen Video increasing from 128×128 quality to 512×512:
On the LaMDA front, Google explored the “limits of co-writing” with AI by having 13 professional writers — including Robin Sloan (known for Mr. Penumbra’s 24-Hour Bookstore where Google’s book scanning hardware plays a role) and Ken Liu (check out Pantheon). You can read the short stories now as part of the Wordcraft Writers Workshop.
Other generative AI work shared today includes AudioLM and DreamFusion:
- “In the same way a language model might predict the words and sentences that follow a text prompt, AudioLM can predict which sounds should follow after a few seconds of an audio prompt.”
- “…text-to-3D is now a reality with DreamFusion, which produces a three-dimensional model that can be viewed from any angle and can be composited into any 3D environment.”
Besides expanded flood and wildfire tracking today, Google announced a multi-year 1,000 Languages Initiative to build an AI model that will support the 1,000 most spoken languages.
FTC: We use income earning auto affiliate links. More.

Comments