
Google Discover, which is arguably a key way that people find stories to read on Android, has a major issue with blatant, barely-masked plagiarism in Web Stories.
Google Discover is prominently placed on mobile devices today, appearing in the Google app, Chrome’s New Tab Page, the Google.com homepage, and the far-left home page of Pixel phones. As such, it can act as a gateway to content around the internet, including news articles, blog posts, Reddit submissions, YouTube videos/shorts, and most recently “Web Stories.”
First introduced to Google Discover in October 2020, Web Stories are a way for web creators to craft short form, visual-heavy narratives in a format akin to Stories in Snapchat and Instagram. In the last two years, Google has made it increasingly easier for anyone to create their own Web Stories, particularly through a WordPress integration.
Inevitably, that ease of use and the prominent placement of Web Stories in Discover has led some bad actors to abuse the system. It’s not uncommon on the internet in general for some to take work that others have done and claim it as their own, though these instances are typically caught by Google’s algorithms and removed from the first pages of search results.
However, these plagiarism protections do not appear, from an outside perspective, to currently apply to the Web Stories that surface in Google Discover. In recent weeks, we have spotted numerous egregious examples of Web Stories in the Discover feed that are outright copies of articles published by outlets including 9to5Google, Android Police, and CNBC. In fact, in our testing, almost every refresh of the Discover feed includes one or more plagiarized Web Stories.
In the screenshots below, we see three examples of this problem in action. The story in the first screenshot, published by “Insane,” uses the headline, graphics, and text from our Bandwidth column. Another example from Insane pulls its content from CNBC.
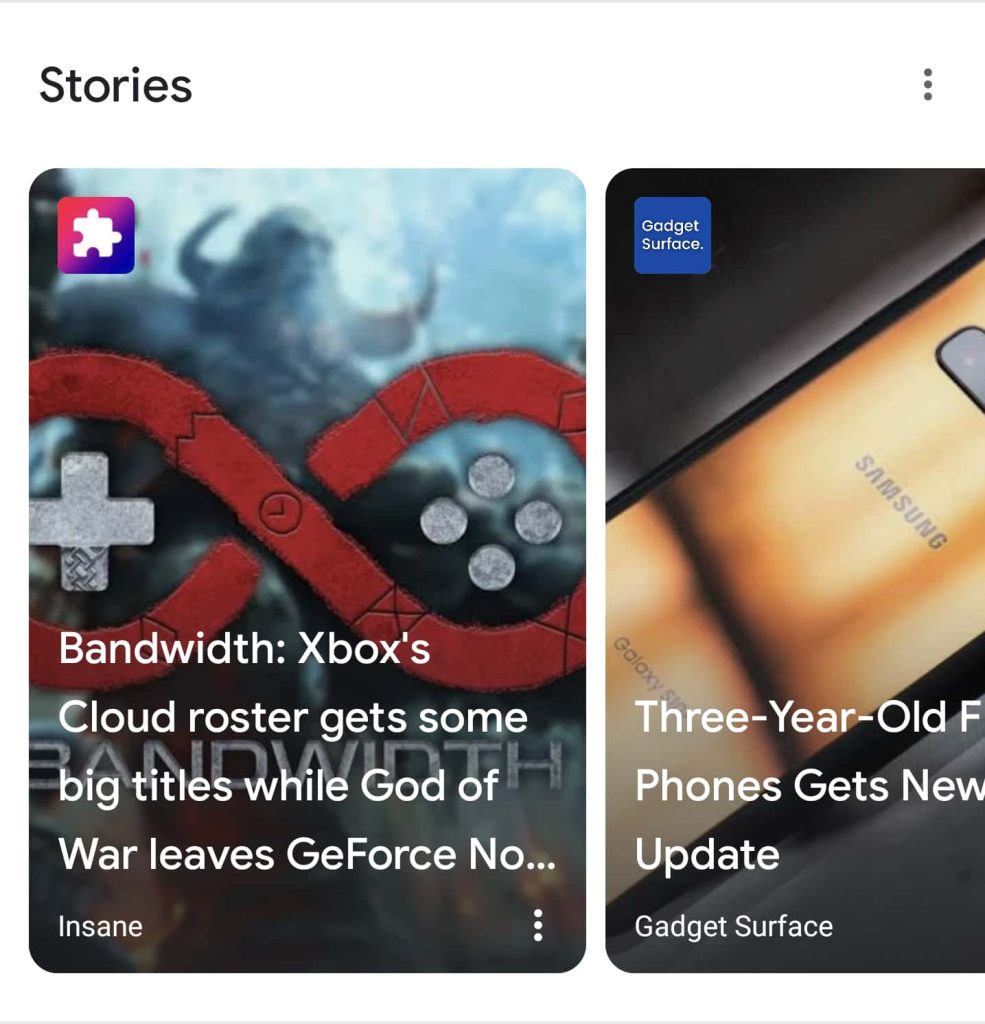
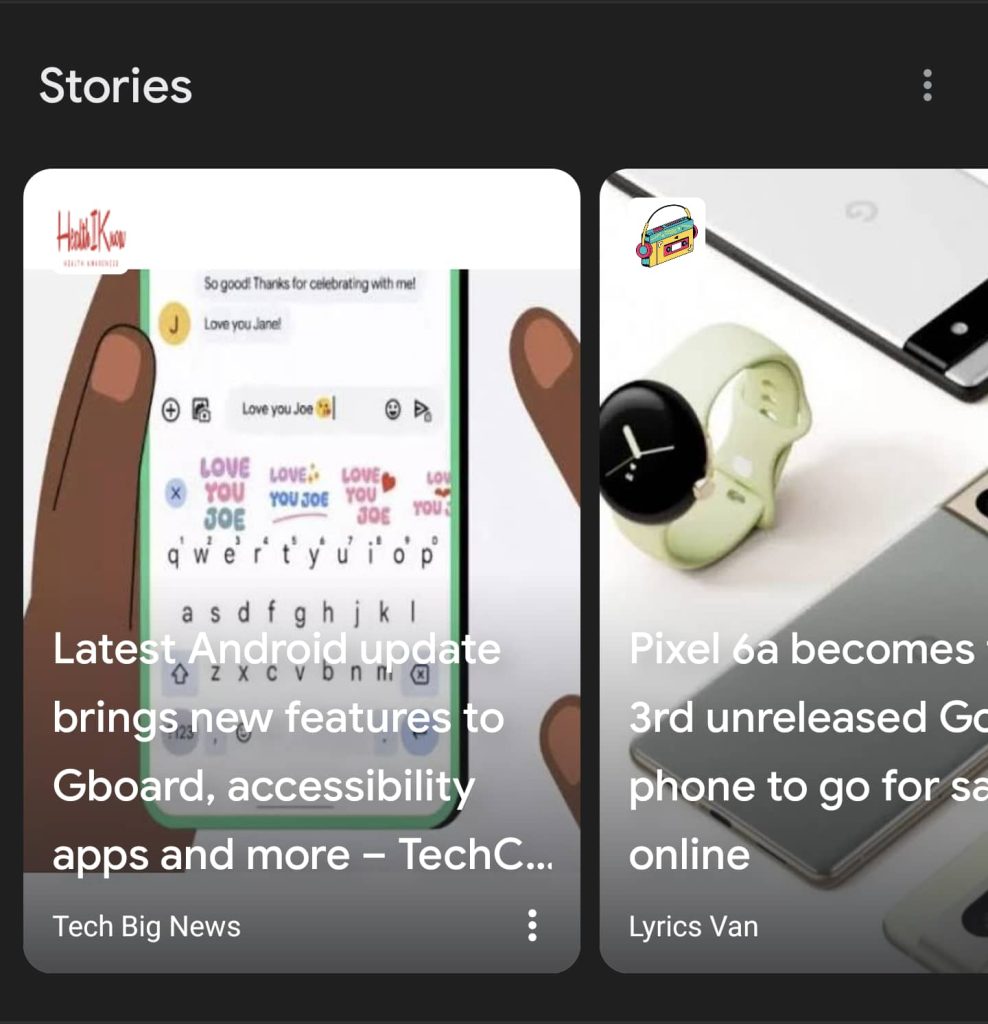
In the second screenshot, there are two side-by-side examples of plagiarized Web Stories. The first, from “Tech Big News,” uses a headline from TechCrunch and consists of nothing but links to plagiarized articles. Next to it, the Web Story from “Lyrics Van” takes the headline of an Android Police article and pairs it with the text of a post from 91mobiles.
So what can be done to curb this issue? In a statement, Google has passed the buck to publishers, pointing to the company’s existing process for legal takedowns. According to the company, this is the primary remedy for Google Search, Discover, and Web Stories.
Web Stories are meant to reflect original works, and we encourage rightsholders to report copyright infringement. If we are notified of content that infringes on someone else’s copyright, we take appropriate action.
— Google spokesperson
Further, Google cited to us the complexities of copyright licensing and potential instances of fair use that it says make it hard to automatically enforce against copyright infringement. Beyond that, we’re told the company’s page ranking system puts a lower value on spam or plagiarized content across Search and Discover, though this does not seem to prevent the stories from appearing in the Web Stories carousel.
The situation as it stands leaves publishers solely responsible for locating and reporting instances of plagiarism of their content. The problem is that there’s no way to prevent a new malicious site from being created once a previous one has been taken down, leaving web creators to play a perpetual game of whack-a-mole.
It’s clear the responsibility for this issue falls upon Google, as the company’s algorithms decide what does or doesn’t appear in each person’s Discover feed. Web Stories should be given the same checks for blatant plagiarism that Google Search results receive. It’s simply ridiculous that this wasn’t built into the format/product from day one, and that Google has shown no intention to address the root of the problem.
FTC: We use income earning auto affiliate links. More.



Comments